PWA and HTTP Caching

In my previous PWA article I've covered PWA basics. In this article I will cover more complex situations where a simple Service Worker is not enough. I will also talk about differences between new Service Worker Cache and HTTP Cache and how they interact. That's because they do interact and not knowing how they work together might cause problems.
I assume you have basic knowledge of PWA and you've seen at least a basic Service Worker. If not, please read my previous article first.
Why is cache so important?
PWA is a webpage that act like a classic application. And classic applications work without Internet connection (at the very least they open up and display a message).
If you don't cache enough:
- your application will not work off-line,
- your application will be slow.
If you cache too much:
- users will get stale data,
- users will not get new functions,
- or worse... users using old version of scripts might try to use APIs that does not exist anymore.
Types of cache
For our purposes there are two types of cache:
- Browser/HTTP Cache – this is the good old cache stored on the user side by the browser. It is mostly controlled by HTTP headers generated by the server. There is no API to control this cache directly from JavaScript, but there are some tricks to bypass Browser Cache. The most common one is to add version or time as a parameter.
- Service Worker Cache – this is a new shiny cache designed for use in a Service Worker. It's not simply a new Cache API. This cache is completely separate from a standard browser cache. It's both stored in a separate place and controlled differently. HTTP headers don't apply to Service Worker Cache.
Cache order
The most important thing you need to know is – by using Service Worker Cache you are not disabling Browser Cache.
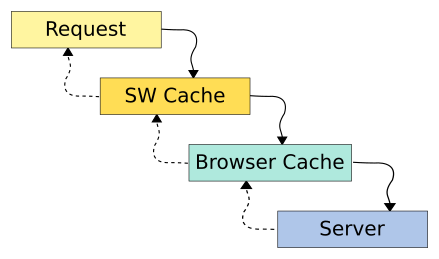
The basic flow is:
- Try Service Worker Cache – if found then response will be served from SW cache (Browser Cache will not be checked).
- Try Browser Cache – if found then response will be served from Browser Cache (server will not receive the request).
- Fetch data from the server – if all else fails, reply with server data.
This means that:
- When Service Worker is registered it can hijack any request.
- Service Worker cannot directly control whether the browser will actually fetch data from server or not.
How to control Browser Cache
Although there are no direct ways to control Browser Cache from JavaScript, there are some techniques you can use to bypass it. Most of this stuff is not new, so I will not dive in too deep.
HTTP headers
This is more of a server side thing, but you have to know at least which headers control Browser Cache. You will not be able to debug your app without that. Also, if you don't have someone else to do the administration work, you should set up at least basic headers on your server.
Basic cache headers
Cache-Control– it is the latest way to control cache. There are many options, but the most important are:Cache-Control: max-age=0– disable cache for given request;Cache-Control: max-age=12– the browser will not even try to load the resource from the server for the next 12 seconds.
Expires– specifies a date when a given resource should be loaded again.ETag– tag that is stored with the resource in Browser Cache. A new version of the resource should have a different tag. The tag is sent back to the server to check if a new version is available.
Note that using ETag is not recommended, partially because Expires and Cache-Control headers are more efficient as the server will not be hit at all.
The downside of Expires and long max-age is that you might need to use cache busting to actually load new versions from the server (see Bypassing cache with JS section below). Or you would need to figure out when the resource becomes stale (when would it actually expire).
Other headers
So is it only ETag, Cache control and Expires... Well, no. There is more. There are some more cases when the browser and the server will agree that content has not been modified. For example if you have mod_cache configured on an Apache proxy, the browser will probably receive a 304 (unmodified) response even without ETag. It might even work without mod_cache for static files (files that are actually on the Apache server, not behind a proxy). This is mostly done with time markers...
But to my knowledge, Cache-Control and Expires (if provided) will overwrite behaviour of other headers. Both are supported in most browsers and you should use one of them if you can.
Server configuration
A minimal Apache (HTTPD) configuration when working with PWA:
FileETag None
Header unset ETag
# disable browser cache for service-worker.js file
<FilesMatch "^(service-worker.js)$">
Header unset Expires
Header set Cache-Control "max-age=0"
</FilesMatch>This basically disables Browser Cache for the service-worker.js file and will not do anything for other resources (other than maybe disabling ETag which you shouldn't use anyway).
Note that the above requires enabling mod_header (e.g. in your httpd.conf).
You can find more advanced configurations and configurations for other servers on h5bp server-configs project. Note that in this project they make some assumptions that might not work for you. Use it cautiously.
Bypassing cache with JS
Let's go back to JavaScript. The cache busting technique is quite popular and old (chances are you already used this).
Cache busting (in its simplest form) is done by requesting a resource with an extra parameter. Instead of app.js you request app.js?v=1 and once the application version changes you request app.js?v=2.
If you have a version in the name of the file (library-1.11.js) you are also fine. It even works better for some automatic proxies. The downside is that you would have to change your application build process to be able to do that for all files. It would also make building the Service Worker more complicated (you would have to rename the files which you want to install).
In a more extreme form, you can do requests with a timestamp (e.g. /api/importantList?t=1525476606771). To get a current timestamp in JS you can use this one-liner: timestamp = (new Date()).getTime();.
Note that you need to be careful if you bypass Browser Cache. If you added a timestamp to each request you would void all efforts browsers do to save bandwidth. You would also bombard your server with pointless requests.
Also note that by doing a request to app.js, then to app.js?v=1 and then to app.js?v=2 you are actually downloading 3 resources. And the browser will probably save the 3 resources to cache. There is no guarantee that after requesting app.js?v=1, the cache for app.js will be removed. If you request app.js again, you might get the same result as the first time. And the opposite is also true – there is no guarantee that app.js will remain in cache. That's the problem with Browser Cache. You can't really control it.
How to control SW Cache
With Browser Cache the browser is responsible to do its magic (with suggestions from the server). With SW Cache you are in full control.
- You can decide if the resource is too young or too old.
- You can rewrite requests (e.g. add a parameter to a request to bypass Browser Cache).
- You can answer with a different resource (e.g. serve
404.pngif you didn't found an image in cache). - You can answer with a cached resource but still make a separate request to the server.
All this is done in the Fetch Event listener. Service Worker is just JavaScript, so you are free to do almost anything in that listener.
Do note that worker scope and standard window scope is not the same. There are some APIs missing (e.g. localStorage is not available). So self in the Service Worker is kind of like window in standard JS, but not exactly the same.
Skip caching some requests
To prevent using SW Cache you simply need to exit the fetch event early (before calling event.respondWith). This way you give control back to the browser which will handle things as if the Service Worker was not registered.
Skip non-GET requests
It's best to start with skipping non-GET requests. Google Chrome does not support POST requests in Service Worker and you probably don't want to cache POST requests anyway (they are usually dynamic).
self.addEventListener('fetch', event => { // skip non-GET requests if (event.request.method !== 'GET') { return; } // make response from cache event.respondWith( // ... ); });
Skip specific URLs
Next, you can skip requests by URL and treat remote requests separately from local requests:
self.addEventListener('fetch', event => { // skip non-GET requests if (event.request.method !== 'GET') { return; } // remote request if (event.request.url.startsWith(self.location.origin)) { let url = event.request.url; // skip all but font requests if (url.search(/^https:\/\/(fonts\.(googleapis|gstatic)\.com)/) < 0) { return; } } // local request else { let localUrl = event.request.url.replace(self.location.origin, ''); // skip all API requests if (localUrl.startsWith('/my-api/')) { return; } } // make response from cache event.respondWith( // ... ); });
You might have noticed that I'm using ES6 syntax (like arrow functions and let). You won't need transpilers (like Babel) for that. The Service Worker will work only for browsers that already support ES6 syntax.
Handling synonymous requests
It's also possible to handle synonyms. For example, / is usually a synonym to /index.html. You can cache / and handle requests for /index.html by rewriting them to / again. This is also useful for SPA applications built with e.g. Angular, Ext JS or ReactJS. HTML is usually the same for all subpages so you will want /search to be treated as a synonym of /. If you are handling parameters (query string) in JavaScript, you will also want to handle /search?query=abc as a synonym too.
This is a simplified implementation of synonyms:
self.addEventListener('fetch', event => { // basic cache search request and options let searchRequest = event.request; let searchOptions = {}; // local, GET request if (!event.request.url.startsWith(self.location.origin) && event.request.method === 'GET') { let localUrl = event.request.url.replace(self.location.origin, ''); if (localUrl.startsWith('/index.html') || localUrl.startsWith('/search')) { // Create fake request to the main resource. // Note that this is just a search request, so we don't have to add headers. let searchRequest = new Request('/'); // Search options for `caches.match` function // See: https://developer.mozilla.org/en-US/docs/Web/API/Cache/match let searchOptions = { ignoreSearch: true, // ignore query string ignoreVary: true, // should skip header matching for `caches.match` }; } } // standard `event.respondWith` with `caches.match` changed to use `searchRequest` and `searchOptions`. event.respondWith( caches.match(searchRequest, searchOptions).then(cachedResponse => { if (cachedResponse) { return cachedResponse; } return caches.open(RUNTIME).then(cache => { return fetch(event.request).then(response => { // Put a copy of the response in the runtime cache. return cache.put(event.request, response.clone()).then(() => { return response; }); }); }); }) ); });
At this point you should notice that your Service Worker might grow to be quite big. You might want to refactor it and start putting functions/classes in separate files.
Removing item from cache
You could do a mechanism to purge SW cache for some resources. To do that, you might use e.g. a parameter in the request.
self.addEventListener('fetch', event => { // skip non-GET requests if (event.request.method !== 'GET') { return; } // purge if (event.request.url.search(/(\?|&)action=purge(&|$)/) > 0) { let searchOptions = { ignoreSearch: true, // ignore query string }; // find and remove request from all SW caches caches.keys().then(keyList => { keyList.forEach(cacheKey => { caches.open(cacheKey).then(cache => { cache.delete(event.request, searchOptions).then(function() { console.log('item removed') }); }); }); }); // not handling the request in SW return; } // make response from cache event.respondWith( // ... ); });
Note that this will only remove the resource from SW cache. Browser might still use its standard cache and the request will not hit the server.
Clearing SW Cache – the escape hatch
Although SW cache is mainly controlled by the worker (and most operations occur in the worker), it is possible to control this cache from standard scripts. It would even be advisable to provide an option to clear this cache in some advanced options. When something goes wrong, you can always ask users to clear their cache.
A simple function to clear SW Cache would be:
/** * Clear all caches of the ServiceWorker. */ function clearServiceWorkerCache() { // make sure new API is supported if (!window.caches) { return; } caches.keys().then(function(names) { for (var index = 0; index < names.length; index++) { var name = names[index]; caches.delete(name); } }); }
You might notice that I'm back to ES5 here (old JS syntax). This is to avoid old IE hiccups. Obviously if you use Babel for all your scripts you don't have to worry about that.